The Why
Congressional offices receive overwhelming amounts of mail expressing all kinds of sentiments. As volume has increased, we’ve watched our clients grow frustrated with their inability to manage the deluge of mail manually. Sometimes it takes overtime or even coming in on the weekend to accurately tag every piece of inbound correspondence by issue and sentiment, whether pro or con. We aim to fix that.
Fireside believes that machine learning — the ability for computers to identify and categorize patterns — has tremendous potential for reshaping how Capitol Hill interacts with its constituency. In every aspect of our lives, from shopping on Amazon to tailoring playlists on Spotify, we leverage machine learning to understand and predict our interests. So we’ve embarked on a project to better understand the capabilities of this technology and its applicability to the unique challenges our clients face on the Hill.
Our priorities going into this project are threefold:
- To discover how machine learning can reduce the human workload while maintaining Fireside’s high standards for privacy and security.
- To visualize an abundance of helpful data points while preserving Fireside’s sleek design.
- To handle complex analyses while being effortless to use.
Our overall goal is to make it easier to better understand constituencies.
Through a grant provided by the Democracy Fund, we started with a cursory exploration into the use of machine learning on constituent correspondence. The findings were encouraging! They informed our decision to move forward in finding a way to successfully apply this technology to the unique data set Congress provides.
Findings
We learned from this process that our world on Capitol Hill is unique. The sheer abundance and complexity that surrounds daily life in a congressional office is simply too great a burden for untrained machines to properly interpret — even when limited to the context of congressional correspondence. The topics and categories determined by un-customized models weren’t specific to politics, let alone congressional issues. The models also had trouble determining sentiment because of the way bills are named. Off-the-shelf models were too generalized and proved to be insufficient for our needs.
Specialized tuning is necessary to accomplish our mission. This means engaging full-time machine learning experts to program and design the systems not only to read text and identify its literal meaning, but to develop an understanding of the sentiment expressed by the author. Take a look at the difference between how generic models performed compared to an expertly trained model.
| Untrained Model | Expertly Trained Model | |
| Health care topics | Care, Watch, Truck | Care, Health, HR 123 |
| Firearms-related categories | Country music | |
| Sentiments | “I oppose the SAFE Act” classified as positive because of the word “safe” | “I oppose the SAFE Act” classified as negative because of the word “oppose” |
To get such improved and nuanced results requires large amounts of data and high-performance hardware. The House’s operating environment generally lacks on-demand access to the computing horsepower required to build specialized models. Because letters often include district-specific issues and display a particular bias, the machine has to be powerful enough to parse the information without skewing the results.
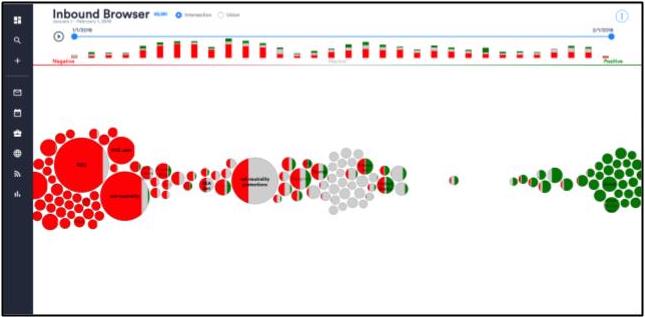
To take advantage of the complex results provided by these new tools, you’ll need sophisticated yet easy-to-understand visualizations. We’ve built a model that is designed with Hill staffers’ needs in mind. You can learn more, log mail, and collect sentiments all at once.

Now what?
Now, we need you. Based on our initial explorations, we’ve determined that not only would machine learning benefit our clients’ daily lives in the short term, but it will help to modernize the way Congress connects with constituents in the long term.
We’ve partnered with machine learning experts Miner & Kasch to deliver this vision to Congress. The more information we can provide to train the system, the better it will be able to perform. So the more offices that help, the faster we can provide results. Please join us in modernizing Congress.